There are a few ways to represent primary keys within a database. The most common way (in my experience) to use auto-incrementing integers. This means that first row’s key will be 1, the second’s will be 2, and so on. When it comes to my preferred style of software development, however, this approach has a major downside: new domain objects must first consult the database to determine their ID.
While I’m far from a domain-driven design (DDD) purist, I like the idea of being able to represent the core domain objects and business logic of an application in complete isolation from the outside world. Having domain objects depend on the database for IDs makes this impossible (or at least very difficult). If only there existed a different kind of unique ID that could be generated by the domain objects themselves without requiring any coordination with an external system…
UUIDs for Life Link to heading
Enter the wonderful Universally Unique Identifier (UUID). These are random values that can be generated without coordination and are extremely unlikely to ever collide with another. This makes them a good candidate for database primary keys! In fact, PostgreSQL has had native support for them since version 8.3. When starting a new project that requires a SQL database, I always default to using UUIDs for primary keys.
They do have at least one downside compared to numeric IDs, though: they take up more space.
Integer primary keys typically occupy either 4 bytes (serial) or 8 bytes (bigserial) per key.
UUIDs, on the other hand, take up 16 bytes per ID (a 12 byte difference, potentially)!
Despite the increased size, I still think they are worth using simply due to the complexity they absolve when generating and working with domain objects.
The Big Migration Link to heading
UUIDs are great, so what’s the problem? Where is the “migration” mentioned in this post’s title? Well, prior to learning about DDD and embracing the magic of UUIDs, Bloggulus was written with numeric primary keys. I wanted to change them but there was a snag: my database was already tracking tens of blogs and hundreds of posts. Therefore, I didn’t want to wipe the database and start from scratch: I needed to migrate it in-place. Here is what the schema looked like at the start:
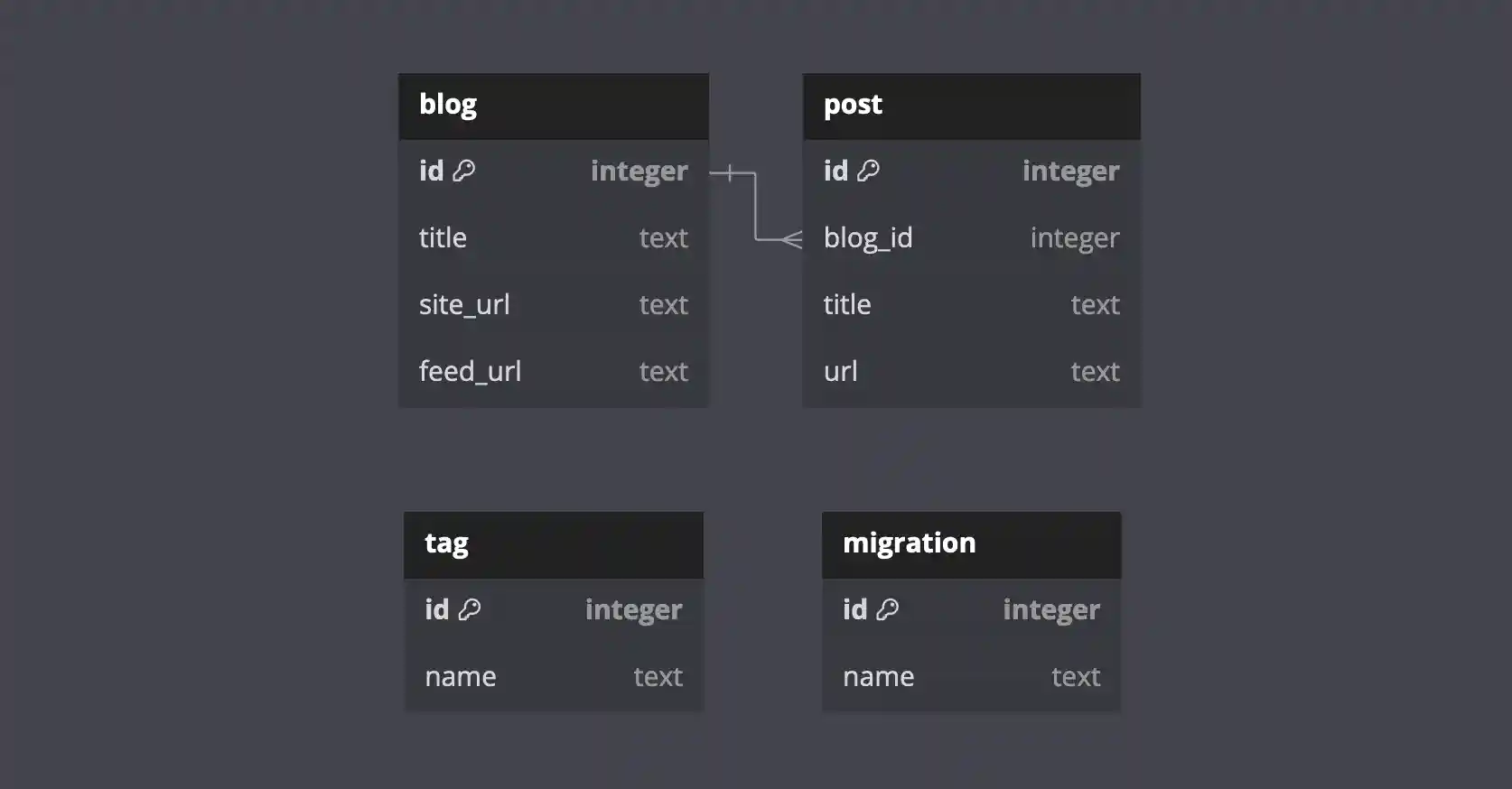
Things were pretty simple back then. These days, Bloggulus has eight tables! It’s certainly not a massive system but still enough to keep me busy.
Anyhow, back to the migration. In short, what we need to do is this: convert every numeric primary key column into a UUID:
-- before
id SERIAL PRIMARY KEY
-- after
id UUID DEFAULT gen_random_uuid() PRIMARY KEY
How can we make this happen? It actually depends on whether or not you have to worry about relationships. The goal of “convert every numeric primary key column into a UUID” implies a knock-on effect: foreign keys also need to be converted to UUIDs while pointing to the same, original row in the other table. My migration also has an extra, self-imposed, and somewhat unnecessary requirement: I still want the each table’s primary key to be the first column.
Easy Case: No Relationships Link to heading
If the data has no relationships, then the command is simple: use ALTER TABLE to directly swap the column’s type. This requires a bit of nuance, though, with respect to defaults. The primary key column’s default must be dropped before swapping the type and then re-established afterward. Lastly, we use gen_random_uuid to generate a fresh UUID for each row.
-- Modify the tag.id column in place.
ALTER TABLE tag
ALTER COLUMN id DROP DEFAULT,
ALTER COLUMN id SET DATA TYPE UUID USING (gen_random_uuid()),
ALTER COLUMN id SET DEFAULT gen_random_uuid();
-- Modify the migration.id column in place.
ALTER TABLE migration
ALTER COLUMN id DROP DEFAULT,
ALTER COLUMN id SET DATA TYPE UUID USING (gen_random_uuid()),
ALTER COLUMN id SET DEFAULT gen_random_uuid();
Hard Case: With Relationships Link to heading
If there are relationships, however, then a few more steps must be taken. Instead of modifying the tables in place, we need to create new tables and carefully copy the existing data such that we don’t lose track of the foreign keys. More specifically, we need to temporarily persist the original IDs of the “parent” table so that the “child” table’s rows can be linked to the parent’s new UUIDs.
Perhaps things will be clearer if we look at a real example:
-- Create the new "parent" table w/ UUID primary key and temporary original_id column.
CREATE TABLE blog_new (
id UUID DEFAULT gen_random_uuid() PRIMARY KEY,
feed_url TEXT NOT NULL UNIQUE,
site_url TEXT NOT NULL,
title TEXT NOT NULL,
etag TEXT NOT NULL DEFAULT '',
last_modified TEXT NOT NULL DEFAULT '',
synced_at TIMESTAMPTZ NOT NULL DEFAULT now(),
created_at TIMESTAMPTZ NOT NULL DEFAULT now(),
updated_at TIMESTAMPTZ NOT NULL DEFAULT now(),
-- temporary
original_id INTEGER
);
-- Create the new "child" table w/ UUID primary key.
CREATE TABLE post_new (
id UUID DEFAULT gen_random_uuid() PRIMARY KEY,
blog_id UUID NOT NULL,
url TEXT NOT NULL UNIQUE,
title TEXT NOT NULL,
content TEXT NOT NULL,
published_at TIMESTAMPTZ NOT NULL,
fts_data TSVECTOR GENERATED ALWAYS AS
(to_tsvector('english', title || ' ' || content)) STORED,
created_at TIMESTAMPTZ NOT NULL DEFAULT now(),
updated_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
-- Populate the new parent table while keeping the original_id around.
INSERT INTO blog_new
(feed_url, site_url, title, etag, last_modified, original_id)
SELECT
blog.feed_url,
blog.site_url,
blog.title,
blog.etag,
blog.last_modified,
-- original_id
blog.id
FROM blog;
-- Populate the new child table while joining to the parent (based on
-- its original_id) to obtain the parent's new UUID primary key.
INSERT INTO post_new
(blog_id, url, title, content, published_at)
SELECT
blog_new.id,
post.url,
post.title,
post.body,
post.updated
FROM post
INNER JOIN blog_new
-- Join on the blog's original_id.
ON blog_new.original_id = post.blog_id;
-- Drop the temporary original_id column from the parent.
ALTER TABLE blog_new DROP COLUMN original_id;
-- Extra cleanup omitted for brevity:
-- 1. Drop old tables.
-- 2. Rename new tables.
-- 3. Rename new table indexes (the auto-generated ones).
-- 4. Add indexes to new tables (the manual ones).
-- 5. Reapply foreign key constraints.
There we go! That was certainly a lot of SQL. I hope that seeing an example makes the process a bit more clear but I apologize if I haven’t done a great job explaining how this works. If you want to see the full migration complete with all of the nuances, take a look.
I’ll say this: the problem of tracking and joining on the original IDs definitely gets more complex the larger your data model becomes. At some scale, I think things could quickly get out of hand. I got luckly, though, and merely had to deal with the simplest of relationships between only two tables.
Conclusion Link to heading
I love using UUIDs for database primary keys. Despite the extra space they occupy, they are more than worth the cost. Being able to decouple domain object ID generation from the database allows me to write the largest and most critical aspects of my application in complete isolation from other systems. Originally, Bloggulus was written with numeric primary keys. This limited my ability to explore the concepts of domain-driven design. I eventually wrote a migration of moderate complexity to convert them to UUIDs and haven’t looked back.
Thanks for reading!