Writing software is hard. Sometimes, I’ll find myself stuck on a problem for days or even weeks. When that happens, I find it useful to write out everything I know about the problem: the nuances, possible solutions, external references, etc. My most recent head-scratcher has been about balancing “purist” REST API design with the needs of a web frontend. I’m beginning to realize a truth: they are different. As always, I’m talking about Bloggulus.
The Problem Link to heading
I’ve recently been working on adding support for individualized feeds.
This means that users can create an account and follow their own favorite blogs.
Under the hood, this involves adding a new many-to-many relationship between accounts and blogs (easy enough).
The problem comes when creating a UI for users to follow and unfollow blogs.
See, from a data model point of view, the state that tracks if a user follows a blog is NOT attached to the blogs table.
To put it another way, the GET /api/v1/blogs endpoint does NOT include an isFollowing field.
Instead, the GET /api/v1/blogs/{blogID}/following endpoint exists to check if a specific blog is being followed by the authenticated user.
Given this limitation, how can we build a page like this? Pardon the ugliness…

N+1 API Calls Link to heading
If the goal is to maintain “REST API purity”, then the frontend has no choice but to make multiple calls. Since the underlying resources are granular and normalized, the frontend needs to collect and aggregate the disparate pieces that compose a single page (or element). For a list of blogs and whether or not the user follows them, this means making one call for the blogs and then N more calls for each one: checking if it is already followed. This pattern is known as the “N+1 Problem” and is well documented.
Optimization: Two Trips Link to heading
Note that this doesn’t necessarily imply N+1 round-trips to the backend. With proper concurrency (like Promise.all), the problem reduces to only two round-trips: one for the blogs and another for their followed status (all at the same time). In pseudocode, this looks something like:
// Make one round-trip to fetch the blogs.
const blogs = await fetch("/api/v1/blogs");
// Make N round-trips simultaneously for their followed status.
const following = await Promise.all(
blogs.map((blog) => fetch(`/api/v1/blogs/${blog.id}/following`))
);
So, the browser makes N+1 API calls to render this page but it only feels like two to the user. Two is definitely better than N, but it still isn’t great user experience. Also, the backend API must be able to handle a high volume of concurrent requests without too much throttling / queueing (or being limited by a DB connection pool size, for example). Otherwise, the user will end up waiting much longer than expected. That being said, can we do better? Can we find a way to make user only have to wait for one round-trip instead of two (or more)?
Optimization: One Trip Link to heading
What if we render the list of blogs immediately after the first round-trip and then display the follow button once the second round of requests returns to the browser? While waiting for that second batch, we could show some sort of loading indicator (like a spinner). Thanks for the awesome features provided by React Router, this is easily doable! The project refers to this behavior as deferred data. By taking the pseudocode above, wrapping it with defer, and rendering the follow/unfollow button inside of an Await block, we can achieve this desired behavior:
async function loader() {
// Fetch list of blogs and wait for the response.
const blogs = await fetch("/api/v1/blogs");
// Start fetching each blog's follow status but don't wait (index by ID).
const following = blogs.blogs.reduce((acc, blog) => {
return {
...acc,
[blog.id]: fetch(`/api/v1/blogs/${blog.id}/following`),
};
}, {});
// Return the blogs (awaited) and following (still waiting).
return defer({ blogs, following });
}
function BlogsPage() {
// Get the blogs and following from the loader.
const { blogs, following } = useLoaderData();
return (
<div>
// For each blog...
{blogs.map((blog) => (
<div>
// Render the title and link immediately.
<Link to={`/blogs/${blog.id}`}>{blog.title}</Link>
// Show a fallback state until the blog's follow status loads.
<React.Suspense fallback={<p>LOADING</p>}>
<Await resolve={following[blog.id]}>
// Access the follow status internally via useAsyncValue.
<FollowUnfollowButton blog={blog} />
</Await>
</React.Suspense>
</div>
))}
</div>
);
}
Now, the user experience is even better. Instead of having to wait for two round-trips before seeing any content, the user only has to wait for one. Sure, they can’t follow any new blogs until their respective requests have finished, but I think the quicker, intermediate rendering is worth it. At least they can see something and verify that the app is working in the meantime.
Recap Link to heading
To summarize, it is possible to structure the frontend data loading such that the user-facing performance converges on a single round-trip. It also means that the backend REST API can stay granular, normalized, and designed around individual resources. This approach does have risks, though. Despite the appearance of quick rendering, we are making a bunch of API requests to the backend. Any one of those requests being slow could impact the responsiveness of the page. Do we really to shift all of this data loading and aggregation responsibility to the client? What other options are there?
BFF Endpoints Link to heading
What if we took the individualized needs of a specific frontend (web, mobile, etc) and built a backend that was tailored to those needs? Instead of only exposing the normalized, underlying data models of the application, what if we exposed the rich, pre-assembled data required to power each page? This way, the task of collecting and aggregating data gets shifted to the backend (instead of making the frontend worry about it). In a single API call, the frontend could get everything needed to render a page (or at least a section of a page). This backend could return JSON or even pre-rendered HTML.
This concept already exists and is known as the “Backend for Frontend Pattern” (often shortened to “BFF”). Similar to the “N+1 Problem”, this pattern is well documented. To summarize the general idea:
Rather than have a general-purpose API backend, instead you have one backend per user experience - a Backend For Frontend (BFF). The BFF is tightly coupled to a specific user experience, and will typically be maintained by the same team as the user interface, thereby making it easier to define and adapt the API as the UI requires.
For my specific problem, a more BFF-oriented solution would be to include an isFollowed: boolean field alongside any blog objects requested by the frontend.
On the backend, I could join through the account_blog table and include this data in a single query.
Then, this page could be powered by one API call and one SQL query.
Now that I mention it… I think I’ve already done this elsewhere in the app.
Articles Link to heading
As it turns out, I’ve already solved a similar problem via the “BFF Endpoint” approach (I just didn’t know it had a name). Quick refresher: blogs can have multiple posts (one-to-many), and posts can have multiple tags (many-to-many). In the API (and database), these are represented as separate resources that can be CRUD’d individually. However, on the frontend, we frequently need to bundle these disparate models together into something useful for the user. Here is a screenshot from the application:
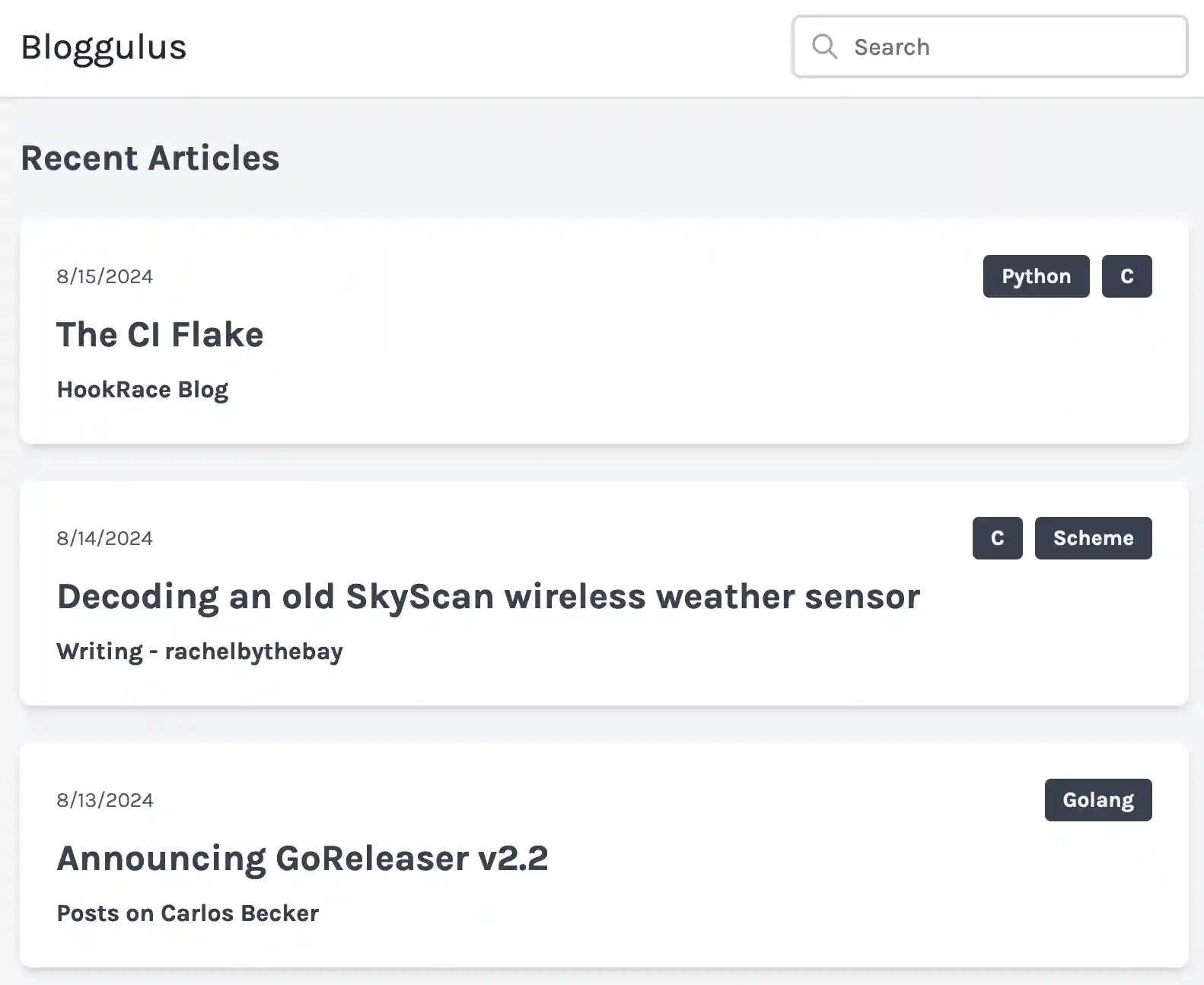
Let’s take the first “article” as an example. You can see how data from all three underlying models are aggregated into a single unit. The published date, post title, and post URL all come from the underlying post model. The blog title and URL come from the blog model. Lastly, the tag names come from the tag model. When I first wrote this page, I faced the same problem: how do I efficently fetch and render this data?
I ended up created new endpoint (and a read-only model) to support it.
I added a new noun to the project: article.
This represents the “post + blog + tags” data needed to power the main page of the application.
With a single call to GET /api/v1/articles, the app’s main feature was ready to rock.
Prior to settling on this approach, I wondered if this was almost a domain-driven design (DDD) problem where the solution was to give “post” a different meaning in different bounded contexts.
Could different user interfaces (web and API) be considered different contexts?
I’m not familiar enough with DDD to really know.
Conclusion Link to heading
What I’ve learned is this: the needs of a REST API (for programmers) are different that a visual frontend (for users). While you can implement a frontend on top of a normalized REST API, you have to take care to avoid the N+1 problem. With some clever loading, the user experience penalty of making waterfall API calls can be greatly minimized. When building a backend, I think it is important to ask: who is this data for and what are their needs? For example, are an API consumer’s expectations the same as a regular web user? Spoiler alert: it depends.
Bloggulus is a small project and I probably don’t need to build two completely separate backends just to accommodate an isFollowing field.
Instead, I could probably find something more balanced and pragmatic.
One idea I have is to simply include the isFollowing field if the requesting user is logged in.
That way, the flow and shape of data is unchanged for regular, anonymous API users.
Or, I just leave the code as-is for now and see how the app’s data needs change and grow over time.
Perhaps future experience with writing more frontends (mobile) and integrations (browser extention) will help inform these architectural decisions.
If you made it all the way to the end, I appreciate you! Is there a one-size-fits-all solution? No, there rarely is. Software is about all balance and tradeoffs. The best you can do is gather experience and knowledge so that your toolbox of options is large enough to handle most scenarios.
Thanks for reading!