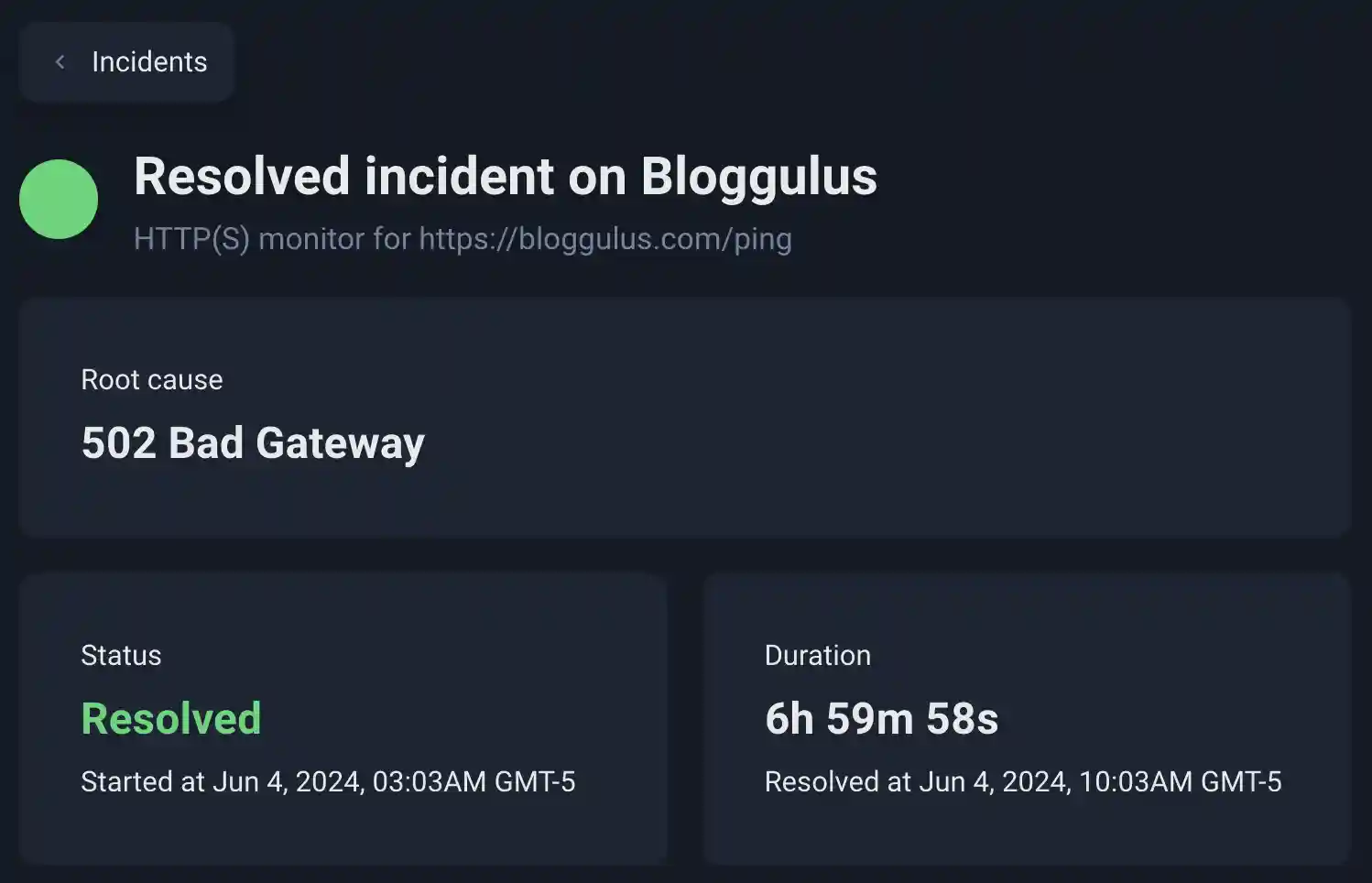
On June 4, 2024, Bloggulus was down for just under 7 hours. Despite being offline for so long, the immediate fix only took only ~30 minutes to find and apply once I became aware of the issue. This post details how I went about fixing the problem and then digs deeper into what actually happened. I also discuss a few gaps in server monitoring and notification delivery.
Bloggulus is Down Link to heading
I didn’t actually become aware of the site being down until I visited it myself and received a 502 Bad Gateway.
This response is sent from Caddy when it cannot communicate with the service it is proxying (the Bloggulus web server).
Why didn’t I know about this sooner?
Despite my UptimeRobot monitor going red within 5 minutes of the outage, I have the notifications configured to be sent to my primary shallowbrooksoftware.com email address. However, since I don’t have this inbox configured on my phone (since it isn’t managed via Google), I had no way to know about it unless I checked for emails on my personal laptop.
Anyhow, back to the action!
The first I did was SSH into the server and check the systemd logs:
Jun 04 14:51:39 bloggulus systemd[1]: Starting bloggulus...
Jun 04 14:51:39 bloggulus bloggulus[37755]: 2024/06/04 14:51:39 ERROR failed to connect to `host=localhost user=bloggulus database=bloggulus`: dial error (dial tcp 127.0.0.1:5432)
Jun 04 14:51:39 bloggulus systemd[1]: bloggulus.service: Main process exited, code=exited, status=1/FAILURE
Jun 04 14:51:39 bloggulus systemd[1]: bloggulus.service: Failed with result 'exit-code'.
Jun 04 14:51:39 bloggulus systemd[1]: Failed to start bloggulus.
Jun 04 14:51:45 bloggulus systemd[1]: bloggulus.service: Scheduled restart job, restart counter is at 4702.
Jun 04 14:51:45 bloggulus systemd[1]: Stopped bloggulus.
The error here is pretty clear: Bloggulus is unable to connect to the database (which runs on the same machine). Let’s see what’s going on with PostgreSQL.
PostgreSQL is Down Link to heading
It is important to understand the architecture of Bloggulus: the Caddy reverse proxy, the Go-based web app, and the PostgreSQL database all run on a single DigitalOcean droplet. Caddy proxies traffic between the internet and Bloggulus while PostgreSQL stores all of the application’s persistent data (blogs, posts, etc).
Checking the database logs confirm that it is also dead:
Jun 04 14:51:36 bloggulus systemd[1]: Starting PostgreSQL Cluster 14-main...
Jun 04 14:51:36 bloggulus postgresql@14-main[37742]: perl: warning: Setting locale failed.
Jun 04 14:51:36 bloggulus postgresql@14-main[37742]: perl: warning: Please check that your locale settings:
Jun 04 14:51:36 bloggulus postgresql@14-main[37742]: LANGUAGE = (unset),
Jun 04 14:51:36 bloggulus postgresql@14-main[37742]: LC_ALL = (unset),
Jun 04 14:51:36 bloggulus postgresql@14-main[37742]: LANG = "en_US.UTF-8"
Jun 04 14:51:36 bloggulus postgresql@14-main[37742]: are supported and installed on your system.
Jun 04 14:51:36 bloggulus postgresql@14-main[37742]: perl: warning: Falling back to the standard locale ("C").
Jun 04 14:51:36 bloggulus postgresql@14-main[37742]: Error: /usr/lib/postgresql/14/bin/pg_ctl /usr/lib/postgresql/14/bin/pg_ctl start -D /mnt/bloggulus_db/data -l /var/log/postg>
Jun 04 14:51:36 bloggulus postgresql@14-main[37742]: 2024-06-04 14:51:36.657 UTC [37747] LOG: invalid value for parameter "lc_messages": "en_US.UTF-8"
Jun 04 14:51:36 bloggulus postgresql@14-main[37742]: 2024-06-04 14:51:36.657 UTC [37747] LOG: invalid value for parameter "lc_monetary": "en_US.UTF-8"
Jun 04 14:51:36 bloggulus postgresql@14-main[37742]: 2024-06-04 14:51:36.657 UTC [37747] LOG: invalid value for parameter "lc_numeric": "en_US.UTF-8"
Jun 04 14:51:36 bloggulus postgresql@14-main[37742]: 2024-06-04 14:51:36.657 UTC [37747] LOG: invalid value for parameter "lc_time": "en_US.UTF-8"
Jun 04 14:51:36 bloggulus postgresql@14-main[37742]: 2024-06-04 14:51:36.657 UTC [37747] FATAL: configuration file "/etc/postgresql/14/main/postgresql.conf" contains errors
Jun 04 14:51:36 bloggulus postgresql@14-main[37742]: pg_ctl: could not start server
Jun 04 14:51:36 bloggulus postgresql@14-main[37742]: Examine the log output.
Jun 04 14:51:36 bloggulus systemd[1]: postgresql@14-main.service: Can't open PID file /run/postgresql/14-main.pid (yet?) after start: Operation not permitted
Jun 04 14:51:36 bloggulus systemd[1]: postgresql@14-main.service: Failed with result 'protocol'.
Jun 04 14:51:36 bloggulus systemd[1]: Failed to start PostgreSQL Cluster 14-main.
What’s up with those locale warnings?
I don’t recall ever seeing them before but my Ansible automation generates and sets en_US.UTF-8 as the default locale for all new servers.
Thinking that this might be weird fluke or something, I rebooted the server.
Unfortunately, that didn’t make a difference: PostgreSQL was still failing to start.
Maybe the server’s baseline configuration got messed up somehow? I decided re-run the playbook that manages the Bloggulus server and all of its components. Since my Ansible roles are idempotent, anything out of alignment should get straightened out and reset to the desired state.
Running Ansible Link to heading
Everything was green (unchanged) except for one task:
- name: Ensure en_US.UTF-8 locale is available
locale_gen:
name: en_US.UTF-8
state: present
become: yes
become_user: root
That’s pretty peculiar.
This task invokes locale-gen to generate the data for the en_US.UTF-8 locale and ultimately store it in /usr/lib/locale/locale-archive.
That being said, the server’s default locale config didn’t change: just the underlying binary data did.
Very odd.
What happens if I try to perform the locale-gen manually?
Manual Locale Generation Link to heading
Let’s give it a shot:
root@bloggulus:~# locale-gen "en_US.UTF-8"
Generating locales (this might take a while)...
en_US.UTF-8.../usr/sbin/locale-gen: line 177: 15179 Killed localedef $no_archive -i $input -c -f $charset $locale_alias $locale
done
Generation complete.
Whoa, what happened there?
The locale-gen command got killed.
Was it from the OOM killer?
Let’s check dmesg:
root@bloggulus:~# dmesg | grep -i kill
[115633.247115] Out of memory: Killed process 15179 (localedef) total-vm:146420kB, anon-rss:134440kB, file-rss:1756kB, shmem-rss:0kB, UID:0 pgtables:328kB oom_score_adj:0
Yep, it sure was! Does this always happen, though? Or does this program only get OOM killed sometimes?
root@bloggulus:~# locale-gen "en_US.UTF-8"
Generating locales (this might take a while)...
en_US.UTF-8... done
Generation complete.
Interesting.
Everything worked fine the second time which indicates that locale-gen can be non-deterministically killed due to the server being out of memory.
This led me to my next question: are there ever package updates (via unattended upgrades) that require locales to be regenerated?
Perhaps locale data changes every once in a while similar to time zone data.
The Smoking Gun Link to heading
Let’s check the apt logs:
Log started: 2024-05-31 07:00:43
(Reading database ... 102795 files and directories currently installed.)
Preparing to unpack .../locales_2.35-0ubuntu3.8_all.deb ...
Unpacking locales (2.35-0ubuntu3.8) over (2.35-0ubuntu3.7) ...
Setting up locales (2.35-0ubuntu3.8) ...
Generating locales (this might take a while)...
en_US.UTF-8.../usr/sbin/locale-gen: line 177: 183068 Killed localedef $no_archive -i $input -c -f $charset $locale_alias $locale
done
Generation complete.
Processing triggers for man-db (2.10.2-1) ...
Log ended: 2024-05-31 07:00:48
There it is!
On May 31, 2024, after updating the locales package, the locale-gen process was killed (most likely by the OOM killer).
This means that the server was in an unstable state since May 31 but didn’t “fail” until June 4 when the server (and therefore PostgreSQL) restarted.
This leads me to the root cause of this problem: the server needs more RAM!
Moving Foward Link to heading
At the bottom of everything, the server ran out of memory. On the surface, however, the problem presented itself more like a small Rube Goldberg machine:
- The OOM killer caused
locale-gento fail after upgrading thelocalespackage. - The lack of a valid
en_US.UTF-8locale caused PostgreSQL to fail to start. - The lack of a running database caused Bloggulus to fail to start.
Regardless of how it happened, the outcome is clear: the server needs more memory. As a direct result of this incident, I’ve bumped the droplet’s RAM from 512MB ($4/month) to 1GB ($6/month). I also installed the UptimeRobot app and enabled push notifications. In the future, I might redeploy Prometheus and start collecting core server metrics again (CPU, RAM, and storage). That way, I can capacity plan proactively and fix these critical problems before they cause 7 hours of downtime.
Thanks for reading!